Scalar User Defined Functions Pitfalls
Dec 29, 2023
4 mins read

Introduction
In my previous article on measuring performance How to Measure Performance, I emphasized that using User Defined Functions (UDFs) is generally a suboptimal choice for achieving high performance in SQL. In this article, I will delve deeper into the reasons behind this assertion and discuss the drawbacks associated with the use of UDFs.
SQL Server provides three types of user-defined functions: scalar-valued, table-valued, and multi-statement table-valued. This post focuses on the first type — scalar-valued functions, which return a single data value.
While developers frequently adhere to programming principles such as DRY (Don’t Repeat Yourself) with precision, applying this principle to SQL through the use of UDFs may not always be the most advantageous approach.
UDFs come with a set of performance-related drawbacks:
- They are always executed single-threaded.
- Tracking them is challenging, and they remain invisible in Actual Execution Plans.
- They have a lot of limitations preventing them from being inlined and, therefore, miss out on optimization by the SQL engine.
- IO statistics are not always directly visible for them, as elaborated further in the mentioned article.
Scalar UDF
Let’s start by defining a simple scalar UDF that returns the number of posts written by a given user in the current year, in the StackOverflow database:
CREATE OR ALTER FUNCTION [dbo].[GetNumberOfPostsInCurrentYear] (@userId int)
RETURNS INT
AS
BEGIN
DECLARE @cnt int;
SELECT @cnt = COUNT(*)
FROM [dbo].Posts
WHERE
CreationDate > DATEFROMPARTS(YEAR(GETDATE()), 1, 1) AND
OwnerUserId = @userId;
RETURN @cnt;
END
GO
And let’s write a simple query, using defined function:
select
top 100
DisplayName,
[dbo].[GetNumberOfPostsInCurrentYear](u.Id) NumberOfPosts
from
[dbo].Users u
where
1 = (select 1)
order by
u.Id
When initially reviewing the estimated execution plan, it includes information about the invoked function, and we even observe a missing index suggestion. Additionally, it is noticeable that the plan is running in a single-threaded mode:
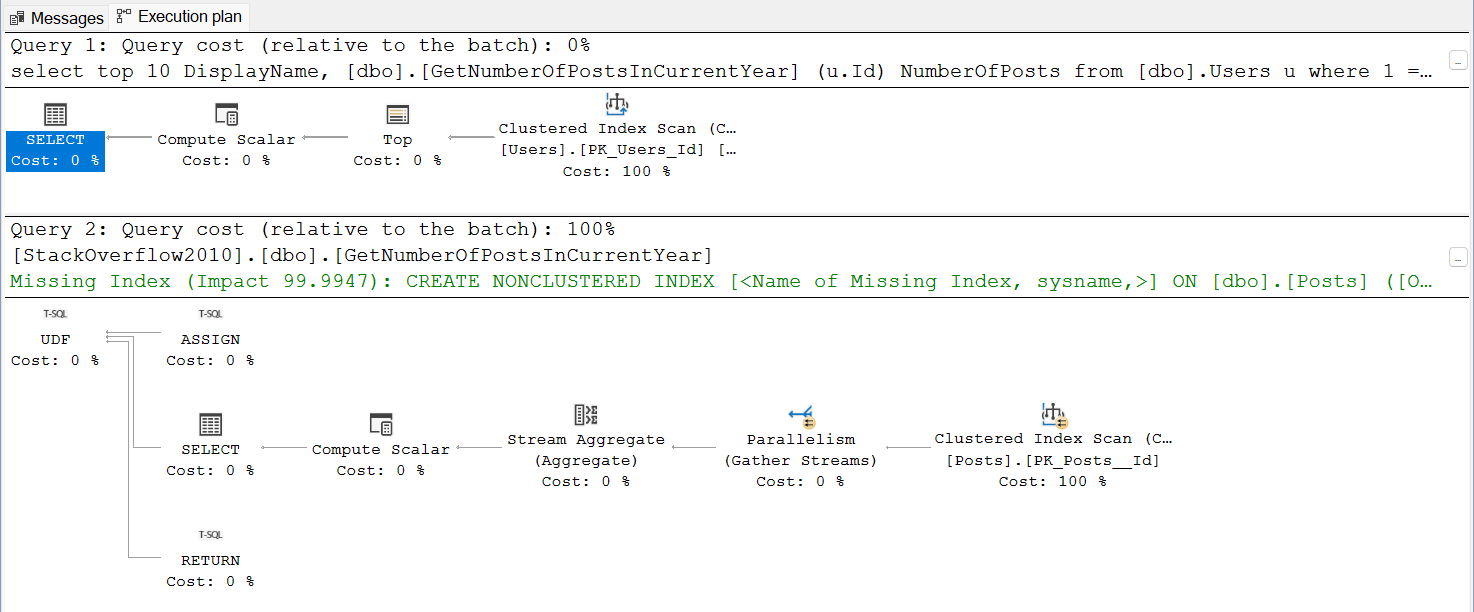
However, estimated execution plans lack comprehensive details. Therefore, during query optimization, I rely on actual execution plans. In this case, information about UDF usage is not immediately visible:
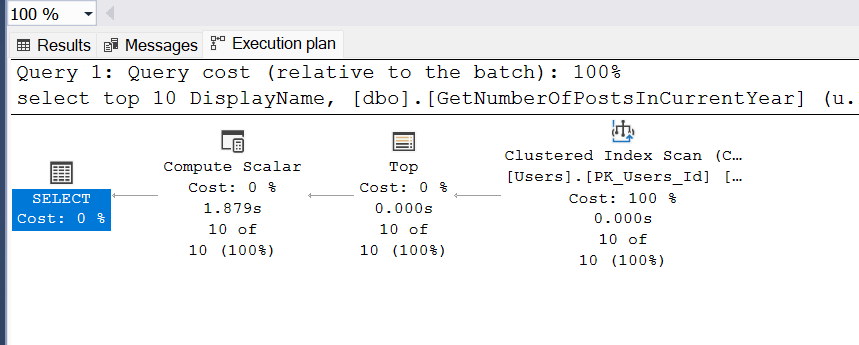
Without index supporting UDF, the Compute Scalar operator consumes a significant amount of time. Upon closer inspection, we discover that details about UDF usage are encapsulated within this operator for our query:


Nevertheless, examining these details is not as convenient as in estimated plans. With the presence of appropriate indexes, the execution time of the operator does not appear suspicious:
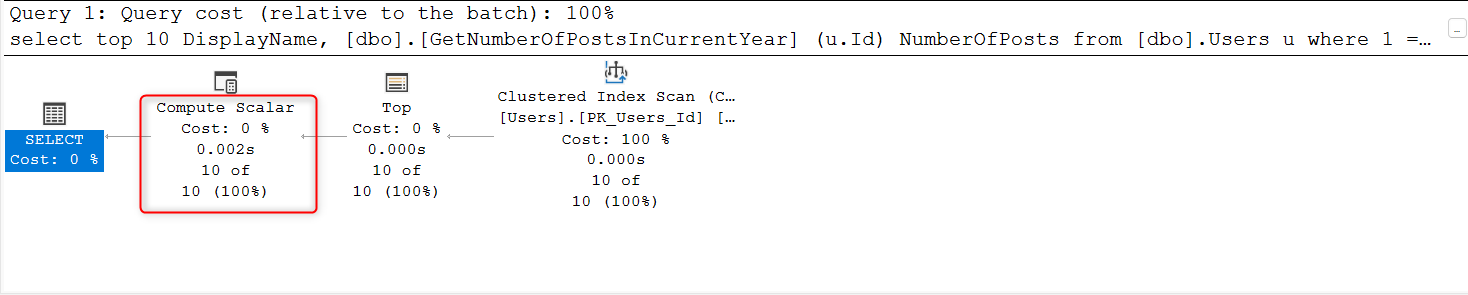
Next important feature of execution plans are details indicating that the engine was unable to go parallel (to verify this, inspect the Properties of the main plan node):

Furthermore, in SQL Server 2022, the engine begins to provide a more detailed reason for non-parallel execution:

Due to the absence of indexes in the Posts table, the total number of logical reads for this execution is 8,456,310.
Optimization
To enhance query execution and to address mentioned problems, one effective approach is to manually inline the function:
select
top 100
DisplayName,
(SELECT COUNT(*)
FROM [dbo].Posts
WHERE
CreationDate > DATEFROMPARTS(YEAR(GETDATE()), 1, 1) AND
OwnerUserId = u.Id) NumberOfPosts
from
[dbo].Users u
where
1 = (select 1)
order by
u.Id
With this optimization, the execution plan now goes in parallel:
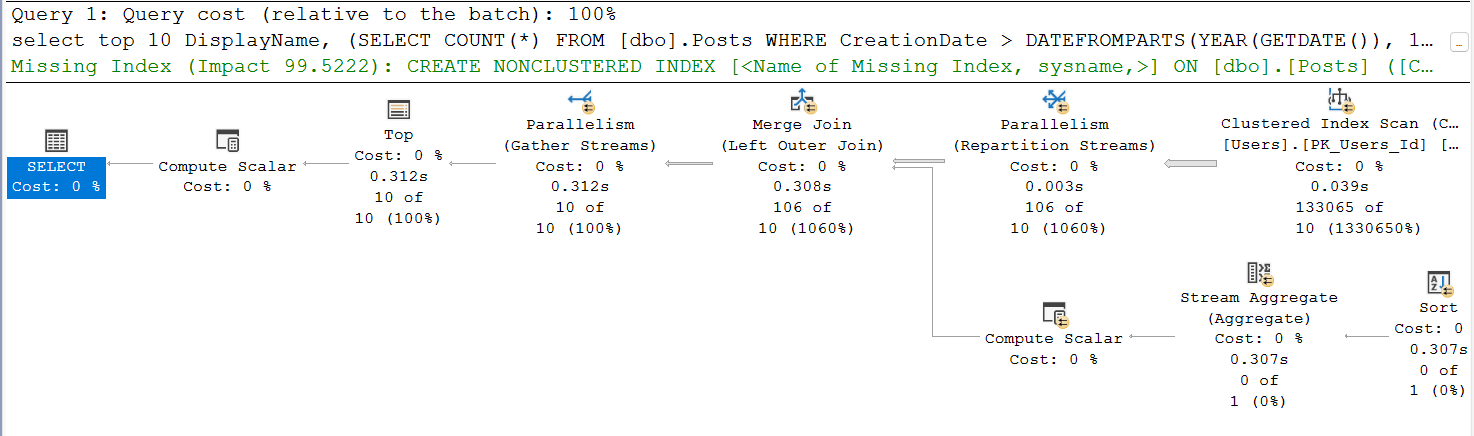
Additionally, the utilization of threads is visible:

The total number of logical reads has been significantly reduced to 849,716. This optimization results in a more efficient and parallelized execution of the query.
Important information
Since SQL Server 2019, Microsoft has introduced numerous enhancements, enabling the inlining of many scalar UDFs. However, it’s important to note that there are various limitations and a few bugs associated with this feature. You can find detailed information about scalar UDF inlining in the MSDN documentation.
In older versions of SQL Server, the presence of even simple UDFs that don’t access data were preventing the engine’s ability to execute queries in parallel. Users working with older SQL Server versions should be cautious, as even functions designed for data formatting will force engine for single-threaded execution.
For users of SQL Server 2019 and later, you can determine if your scalar UDFs can be inlined by executing the following query:
select
OBJECT_NAME(object_id) as ObjectName,
case is_inlineable
when 0 then 'Not Inlineable'
when 1 then 'Inlineable'
end as [Status]
from
sys.sql_modules
However, due to numerous limitations that can prevent functions from being inlined, I prefer not to use them as my first choice. When optimizing queries, removing scalar UDFs is typically one of the first actions I take, especially when it becomes apparent that the query cannot be parallelized due to the use of UDFs.
If you like this article, please share it via your social media: