Selecting Columns in SQL Query for .NET Applications
May 1, 2023
8 mins read

Introduction
When working with ORMs in C#, selecting columns is often neglected, and it may not seem very important at first glance. However, selecting unnecessary data can pose other threats beyond just sending more data through the network. In this post, I will explore these threats.
To demonstrate this, I will be using a 10GB StackOverflow dump. The dump does not have any non-clustered indexes, and I will not be creating any additional indexes at the beginning, since 10GB is not that big. However, we will create some indexes later on to show performance improvements.
Let’s say we want to display the titles of 200 posts from StackOverflow with the names of their authors. We also want to ensure that the posts are older than a given date and sorted in descending order. This example is entirely made up, but it serves to illustrate how SQL estimations can be unpredictable.
All columns at once
Retrieving data from all columns is a fairly straightforward task. When working with NHibernate, as I will demonstrate in this post, we need to define an entity and an additional class that defines the mapping for that entity. Afterward, we can begin selecting data from the database. Assuming you are familiar with the basics of ORM mappers and NHibernate in particular, I will not present the C# code for mapping here. However, if you are interested, you can find the code in this Github repository.
To retrieve data from the database, we can use the following query:
var posts =
await session
.Query<Post>()
.Fetch(x => x.OwnerUser)
.Where(x => x.CreationDate < new DateTime(2010, 1, 1))
.OrderByDescending(x => x.CreationDate)
.Take(200)
.ToListAsync();
NHibernate for this code, generates for us the following SQL query:
select
post0_.Id as id1_0_,
user1_.Id as id1_1_1_,
post0_.AcceptedAnswerId as acceptedanswerid2_0_,
...
post0_.OwnerUserId as owneruserid20_0_,
user1_.AboutMe as aboutme2_1_1_,
user1_.Age as age3_1_1_,
...
user1_.AccountId as accountid14_1_1_
from
dbo.Posts post0_
left outer join dbo.Users user1_ on post0_.OwnerUserId=user1_.Id
where
post0_.CreationDate<@p0
order by
post0_.CreationDate desc
OFFSET 0 ROWS FETCH FIRST @p1 ROWS ONLY;
@p0 = 2010-01-01T00:00:00.0000000 [Type: DateTime2 (8:0:0)],
@p1 = 200 [Type: Int32 (0:0:0)]
I have made some slight revisions to make the statement more concise and easier to read:
For readability, I have removed most of the columns from the query. As a result, we are effectively performing a “SELECT *” and fetching all the columns of the table.
Here is the query plan that was generated by SQL Server for this query:
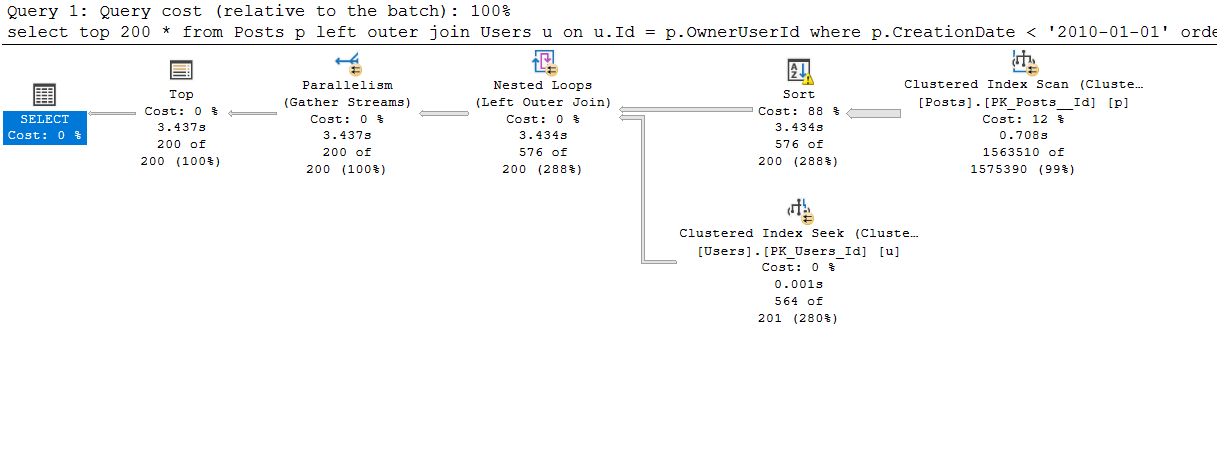
The query plan reveals a Sort operator, which shows that SQL Server estimated that 3613 MB would be required to fetch 200 rows, and the Sort operator had to spill data to disk as the estimate was insufficient.
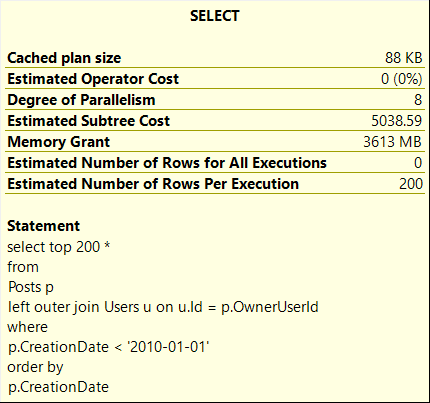
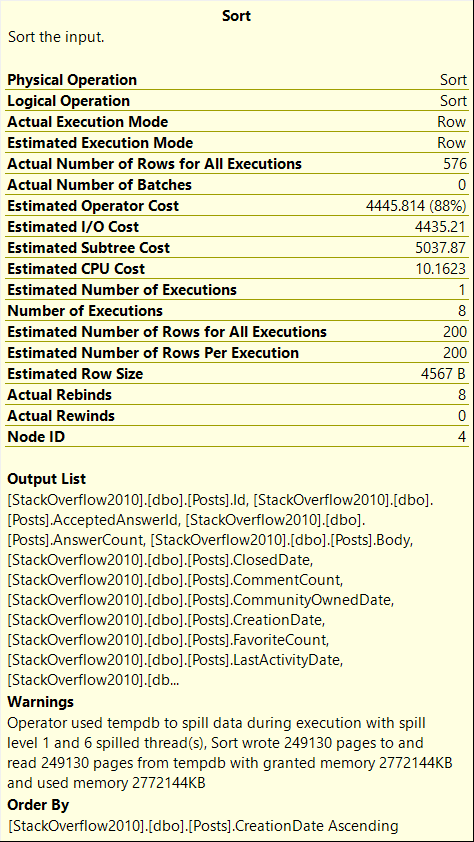
In fact, the SQL Server estimated even more memory than what was actually used. It was estimated to be 8.8GB, but since my server was only able to use 20GB, the SQL Server limited the single query to use 3613MB. As a general rule, a single query can use up to 18% of the maximum server memory (Max Server Memory * 0.18).
Fetching only necessary columns
Now, let’s take a look at how things change when we select only the necessary columns. There are several ways to achieve this, but I find adding a “Select” statement to our LINQ query the most convenient approach:
var posts =
await session
.Query<Post>()
.Fetch(x => x.OwnerUser)
.Where(x => x.CreationDate < new DateTime(2010, 1, 1))
.OrderByDescending(x => x.CreationDate)
.Take(200)
.Select(x => new { x.Title, x.CreationDate, x.OwnerUser.DisplayName })
.ToListAsync();
And result query:
select
post0_.Title as col_0_0_,
post0_.CreationDate as col_1_0_,
user1_.DisplayName as col_2_0_
from
dbo.Posts post0_
left outer join dbo.Users user1_ on post0_.OwnerUserId=user1_.Id
where
post0_.CreationDate<@p0
order by
post0_.CreationDate desc
OFFSET 0 ROWS FETCH FIRST @p1 ROWS ONLY;
@p0 = 2010-01-01T00:00:00.0000000 [Type: DateTime2 (8:0:0)],
@p1 = 200 [Type: Int32 (0:0:0)]
At first glance, the query plan looks similar, but the estimates have changed, and the memory grant is significantly better. Additionally, there is no longer any spilling to disk:
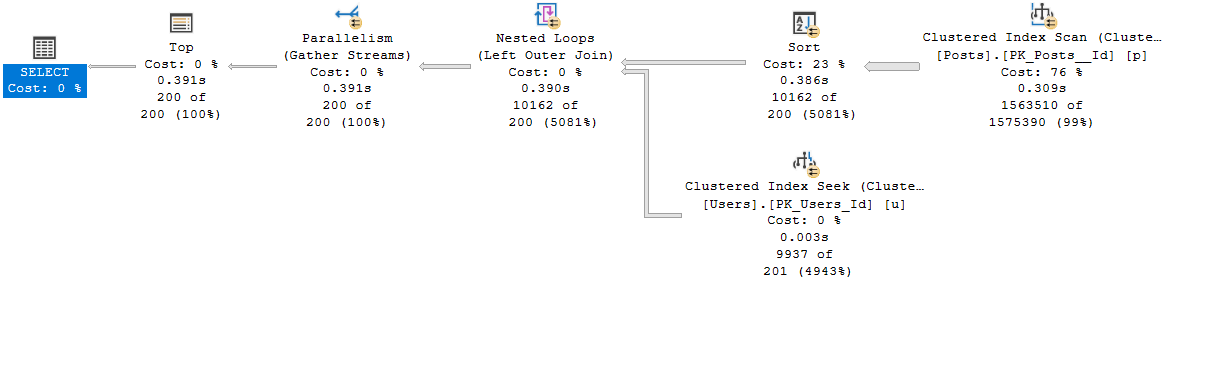
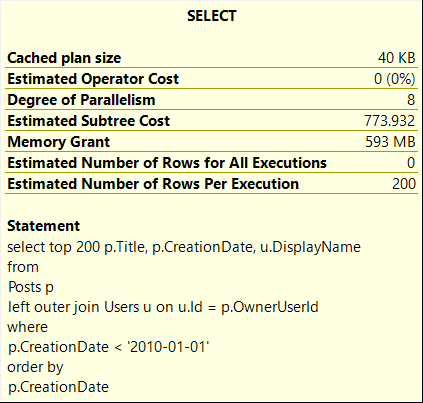
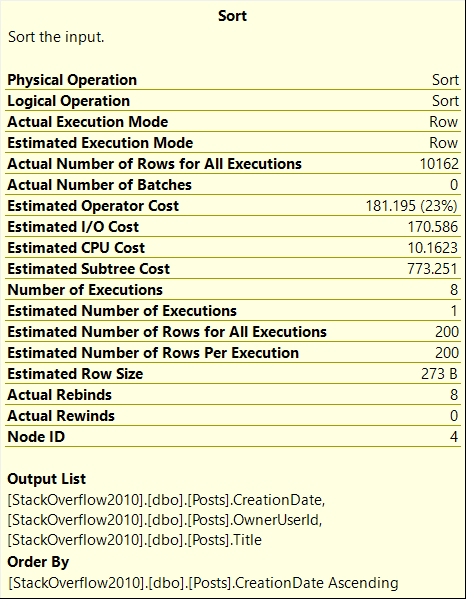
The memory grant of over 500MBs for selecting only 200 rows may seem excessive. However, SQL requires this much memory because we are selecting the Title column, which can contain up to 250 characters. It’s generally advisable not to include large string columns “for future needs” in all queries.
Fixing problem by adding an index
In some cases, having a query with a memory grant of 500MB may be acceptable, but it also depends on how frequently the query is executed. In such scenarios, it might be crucial to eliminate the memory grant altogether. To achieve this, we can simply add an index:
CREATE INDEX CreationDate_Includes
ON Posts (CreationDate)
INCLUDE (OwnerUserId, Title)
WITH(DATA_COMPRESSION = ROW);
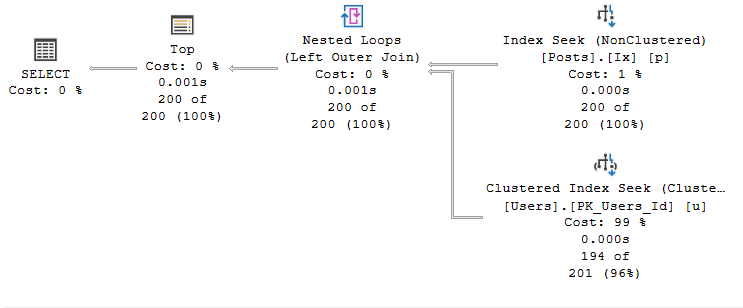
For the second query, since the data is already sorted in the index and the index itself covers all the selected columns, the resulting execution plan is perfect.
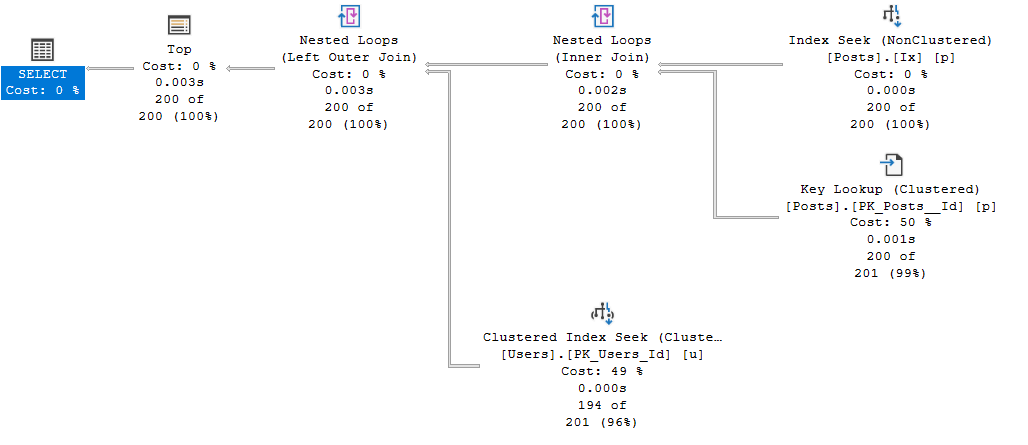
For the first query, SQL will still require additional lookups. However, unlike the previous case, sorting is not necessary.
Other ways to prevent high memory grants
If, for some reason, adding an index is not feasible, but the memory grant is still unacceptably high, one option is to split the query into two, which can reduce the memory grant:
var post_ids = await session
.Query<Post>()
.Where(x => x.CreationDate < new DateTime(2010, 1, 1))
.OrderByDescending(x => x.CreationDate)
.Take(200)
.Select(x => x.Id)
.ToListAsync();
var posts = await
session
.Query<Post>()
.Fetch(x => x.OwnerUser)
.Where(x => post_ids.Contains(x.Id))
.Select(x => new { x.Title, x.CreationDate, x.OwnerUser.DisplayName })
.ToListAsync();
It’s important to keep in mind that NHibernate generates a list of parameters for the query, and if the number of parameters varies on different executions, it may affect the query execution plan cache. Additionally, running two queries without supporting indexes will result in a high number of logical reads.
.Net Runtime
The subsequent issues are more noticeable, as they occur more frequently. They are linked to the .Net Garbage Collection and the additional time required to send data to the application server. The mapping time increases and more pressure is placed on the .Net GC as the number of columns retrieved increases. While high memory grants are connected to sort operators, and not every execution plan requires sorting, retrieving data is the primary goal of most queries. So, neglecting column selection can result in a lot of queries having a greater impact on application performance than they should.
As an example, consider the following benchmark for our test query:
| Method | n | Mean | Error | StdDev | Ratio | RatioSD | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|---|---|
| Select | 200 | 1.480 ms | 0.0286 ms | 0.0391 ms | 0.14 | 0.01 | 242.71 KB | 0.04 |
| AllColumns | 200 | 10.303 ms | 0.1984 ms | 0.2205 ms | 1.00 | 0.00 | 5802.53 KB | 1.00 |
| AllColumns_Stateless | 200 | 9.395 ms | 0.1037 ms | 0.0866 ms | 0.91 | 0.02 | 5773.82 KB | 1.00 |
| NVarchar_Excluded | 200 | 6.008 ms | 0.0896 ms | 0.0795 ms | 0.58 | 0.01 | 4457.36 KB | 0.77 |
| Select | 2000 | 7.390 ms | 0.1472 ms | 0.3526 ms | 0.06 | 0.00 | 1834.67 KB | 0.03 |
| AllColumns | 2000 | 117.382 ms | 2.1241 ms | 3.3690 ms | 1.00 | 0.00 | 57071.23 KB | 1.00 |
| AllColumns_Stateless | 2000 | 120.343 ms | 2.3064 ms | 2.5635 ms | 1.02 | 0.04 | 56804.2 KB | 1.00 |
| NVarchar_Excluded | 2000 | 70.047 ms | 1.3871 ms | 1.5974 ms | 0.60 | 0.02 | 44183.93 KB | 0.77 |
I tested select for 200 and 2000 rows. I didn’t clean execution plan cache for different arguments and, as we saw earlier, NH is parametrizing number of rows to fetch. In this particular case execution plan would be same. At 4th test, I removed 2 nvarchar columns, to make sure that there are no huge texts in the examinated data set, which influece allocated memory too much.
Other problems with Select *
Besides the potential issues of hidden memory grants and increased execution time, selecting all columns each time can also create other problems that should be taken into consideration. For instance, it can make the workflow more prone to changes in the future, and it can make the job of SQL administrators more complicated.
Here are a couple of examples:
- If new columns need to be added to existing tables, and those columns require a type of nvarchar(max) to store really long descriptions, all previously efficient queries may suddenly behave differently. This can cause problems for both developers and administrators.
- On the other hand, if you only select the columns that are necessary to support business needs, there is a higher chance of using covering indexes. By selecting fewer columns, you give SQL administrators more opportunities for optimization.
Conclusions
As demonstrated, selecting only the necessary columns can result in significant time and memory savings on both the SQL Server and the application side. The extent of this impact may vary depending on the table and query in question. While it may not be practical to measure this for every query, it is generally advisable to follow the rule of thumb to select only the columns that are required for further processing.
If you like this article, please share it via your social media: